前言
这是一个关于使用transformer-based模型(如BERT)来预测股票市场的项目。这些模型可以处理序列文本数据并学习大型文本中的标记之间的关系,例如金融和法律数据集。Twitter是金融文本的最大来源之一,可以从推文中识别各种公司的市场趋势。为了实现金融文本和市场之间的整体关系,需要一种高效的预测机制。该项目调查了与股票市场相关的推文,以预测相关的股票走势。使用transformer-based模型,例如BERT,执行序列分类,以理解文本输入,并利用这些模型来预测股票走势。
数据集
股票数据可以分为以下9组:基本材料、消费品、医疗保健、服务、公用事业、企业集团、金融、工业品和技术。本项目使用了StockNet数据集。该项目专注于对特定股票在特定日期上的二元分类(即高或低)的预测。为了生成目标变量,每天的运动百分比被推导出来。为了解决运动百分比极小的股票问题,运动百分比≤0.5%的股票被归类为0(低),运动百分比>0.5%的股票被归类为1(高)。使用上述设置,共识别出26623个目标,其中13368个目标具有正标签(即1),13255个目标具有负标签(即0)。来自StockNet数据集的推文已根据其时间戳链接到其目标股票。为了预测特定目标日d上股票S的股票运动,考虑了从d-t天的股票市场关闭到目标日d的当前开放之间发布的推文。这样做的原因是为了防止未来信息进入目标日d的预测。经过实验,考虑了3天的滞后。
实验方案
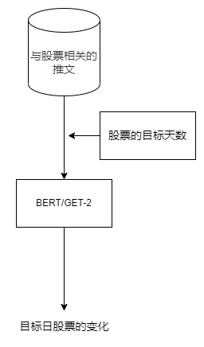
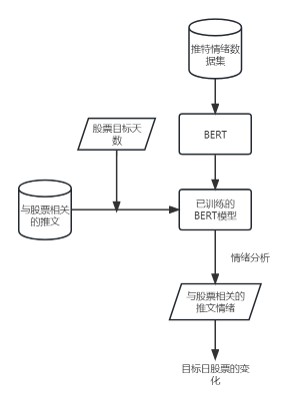
这篇文章中提到了两种方法来预测股票走势。第一种方法是将与股票S相关的推文输入BERT中,以训练模型来预测股票走势。模型可以根据从文本语料库中学到的信息直接预测股票走势(即0/1)。第二种方法是系统利用一个大型的推特数据集,其中包含大约160万个样本。BERT模型在这160万个推文样本上进行训练,以预测情感。这个训练好的模型被用来预测StockNet Twitter数据集上的情感。对于目标股票S,在目标交易日d上,计算推文的情感平均值,并将其与目标交易日d上目标股票S的股票走势进行比较。
方案1
方案2
微调策略
1. 层间学习率下降
下面是一个具有分层学习率衰减的线性调度器的示例:

def bert_base_adamw_llrd(model):# 定义一个函数,用于创建基于BERT模型和AdamW优化算法的优化器对象,并设置学习率衰减策略
"""
该函数用于创建基于BERT模型和AdamW优化算法的优化器对象,并设置学习率衰减策略。
Args:
model: 需要进行优化的模型对象。
Returns:
创建好的AdamW优化器对象。
"""
opt_parameters = []# 定义一个空列表,用于存储优化器需要更新的参数及其对应设置
named_parameters = list(model.named_parameters()) # 获取模型中所有命名参数(即参数名和参数值)并转换为列表
no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"]# 定义一个列表,包含不需要进行权重衰减操作的参数名后缀
init_lr = 3.5e-6
head_lr = 3.6e-6
lr = init_lr
# 从命名参数中筛选出包含"pooler"或"regressor"的参数,并根据是否在no_decay中分为两组
params_0 = [p for n,p in named_parameters if ("pooler" in n or "regressor" in n)
and any(nd in n for nd in no_decay)]
params_1 = [p for n,p in named_parameters if ("pooler" in n or "regressor" in n)
and not any(nd in n for nd in no_decay)]
# 为这两组参数创建一个字典,指定学习率和权重衰减系数,并将其添加到优化器的参数列表中
head_params = {"params": params_0, "lr": head_lr, "weight_decay": 0.0}
opt_parameters.append(head_params)
head_params = {"params": params_1, "lr": head_lr, "weight_decay": 0.01}
opt_parameters.append(head_params)
# 从第11层到第0层遍历编码器的每一层
for layer in range(11,-1,-1):
# 从命名参数中筛选出属于当前层的参数,并根据是否在no_decay中分为两组
params_0 = [p for n,p in named_parameters if f"encoder.layer.{layer}." in n
and any(nd in n for nd in no_decay)]
params_1 = [p for n,p in named_parameters if f"encoder.layer.{layer}." in n
and not any(nd in n for nd in no_decay)]
# 为这两组参数创建一个字典,指定学习率和权重衰减系数,并将其添加到优化器的参数列表中
layer_params = {"params": params_0, "lr": lr, "weight_decay": 0.0}
opt_parameters.append(layer_params)
layer_params = {"params": params_1, "lr": lr, "weight_decay": 0.01}
opt_parameters.append(layer_params)
# 每遍历一层,就将学习率乘以一个衰减因子(这里是0.9)
lr *= 0.9
# 从命名参数中筛选出包含"embeddings"的参数,并根据是否在no_decay中分为两组
params_0 = [p for n,p in named_parameters if "embeddings" in n
and any(nd in n for nd in no_decay)]
params_1 = [p for n,p in named_parameters if "embeddings" in n
and not any(nd in n for nd in no_decay)]
# 为这两组参数创建一个字典,指定学习率和权重衰减系数,并将其添加到优化器的参数列表中
embed_params = {"params": params_0, "lr": lr, "weight_decay": 0.0}
opt_parameters.append(embed_params)
embed_params = {"params": params_1, "lr": lr, "weight_decay": 0.01}
opt_parameters.append(embed_params)
# 使用优化器的参数列表和初始学习率创建一个AdamW优化器对象
return AdamW(opt_parameters, lr=init_lr)
第二种实现分层学习率衰减(或区分微调)的方法是将层分组到不同的集合中,并对每个集合应用不同的学习率。我们将其称为分组LLRD。
使用一个名为roberta_base_AdamW_grouped_LLRD的新函数,我们将roberta-base模型的12个隐藏层分成3组,其中嵌入附加到第一组。
下面是一个具有分组LLRD的线性调度器的示例:
- Set 1 : Embeddings + Layer 0, 1, 2, 3 (learning rate: 1e-6)
- Set 2 : Layer 4, 5, 6, 7 (learning rate: 1.75e-6)
- Set 3 : Layer 8, 9, 10, 11 (learning rate: 3.5e-6)
与第一种方法相同,我们使用3.6e-6作为池化器和回归器头部的学习率,略高于顶层。

def bert_base_adamw_grouped_llrd(model):
opt_parameters = [] # 创建一个空列表,用于存储优化器的参数
named_parameters = list(model.named_parameters()) # 获取模型中所有命名参数,并转换为列表
no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"]# 定义不需要进行权重衰减的参数名
set_2 = ["layer.4", "layer.5", "layer.6", "layer.7"]
set_3 = ["layer.8", "layer.9", "layer.10", "layer.11"]
init_lr = 1e-8
# 定义第二组和第三组参数名,这些参数的学习率会比初始学习率(1e-8)高1.75倍和35倍
for i, (name, params) in enumerate(named_parameters):
weight_decay = 0.0 if any(p in name for p in no_decay) else 0.01# 根据参数名判断是否需要进行权重衰减,如果是,则设为0,否则设为0.01
lr = init_lr
lr = init_lr * 1.75 if any(p in name for p in set_2) else lr
lr = init_lr * 35 if any(p in name for p in set_3) else lr
opt_parameters.append({"params": params,
"weight_decay": weight_decay,
"lr": lr})# 将当前参数及其权重衰减和学习率添加到优化器参数列表中
return AdamW(opt_parameters, lr=init_lr)# 返回一个使用AdamW优化器和分组LLRD策略的优化器对象
2. 预热步骤
对于我们使用的线性调度程序,我们可以应用热身步骤。例如,应用50个热身步骤意味着学习率将在前50个步骤(热身阶段)期间从0线性增加到优化器中设置的初始学习率。之后,学习率将开始线性降低到0。

下图显示了第50步的相应层的学习率。这些是我们为优化器设置的学习率。

scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 50,
num_training_steps = total_steps)
3. BERT的预训练层重新初始化
BERT有12层,BERT的每一层都捕捉各种信息。较低的层包含低级表示并存储通用信息。任务相关信息存储在BERT的顶层,靠近输出的层中。Revisiting few-sample BERT fine-tuning文中建议,重新初始化这些顶层将提高BERT在多个下游任务上的性能。基于他们的工作,BERT的前3层已被重新初始化,用于直接股票运动预测模型。
from transformers import BertForSequenceClassification, AdamW, BertConfig
from transformers import logging
logging.set_verbosity_warning()
logging.set_verbosity_error()
reinit_layers = 3# 设置重新初始化的层数为3
_model_type = 'bert'
_pretrained_model = 'bert-base-uncased'
config = BertConfig.from_pretrained(_pretrained_model)# 从预训练模型创建配置对象
model = BertForSequenceClassification.from_pretrained(_pretrained_model, num_labels = 2,
output_attentions = False,
output_hidden_states = False)# 从预训练模型创建一个用于序列分类的Bert模型,并设置输出类别数为2,不输出注意力和隐藏状态
if reinit_layers > 0:
print(f'Reinitializing Last {reinit_layers} Layers ...')
encoder_temp = getattr(model, _model_type)# 获取Bert模型中的编码器部分,并赋值给encoder_temp变量
for layer in encoder_temp.encoder.layer[-reinit_layers:]:# 遍历编码器中最后几层
for module in layer.modules():
if isinstance(module, nn.Linear):# 如果子模块是线性层,则对其权重和偏置进行正态分布初始化或置零操作
module.weight.data.normal_(mean=0.0, std=config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):# 如果子模块是嵌入层,则对其权重进行正态分布初始化或置零操作
module.weight.data.normal_(mean=0.0, std=config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm): # 如果子模块是层归一化,则对其偏置置零,对其权重设为1.0
module.bias.data.zero_()
module.weight.data.fill_(1.0)
print('Done.!')
model.cuda()
结果
微调Bert
| Models | Accuracy | MCC |
|---|---|---|
| 基础BERT | 46.7 | -0.03 |
| BERT + 层间学习率下降 | 47.8 | 0.005 |
| BERT + 分组层间学习率下降 | 51 | 0.007 |
| BERT + 分组层间学习率下降 + 预训练层重新初始化 + 50步预热训练 | 53 | 0.0344 |
试验方案对比
| Models | Accuracy | MCC |
|---|---|---|
| BERT 直接预测 | 53 | 0.0344 |
| BERT 通过市场情绪预测 | 52.6 | 0.026 |
此外展示上述两种方案模型在训练对数据集预测
- 直接预测
| stock_date | movement_percent | stock_symbol | market_binary | tweet | predictions | true_labels | pred_probs |
|---|---|---|---|---|---|---|---|
| 2015-10-01 | -6.53e-03 | AAPL | 0 | rt URL rt stockaced : bzq proshares ultrashort… | 1 | 0 | [0.49454588, 0.50545406] |
| 2015-10-01 | -7.36e-03 | ABB | 0 | rt AT_USER icymi : $ abb energizes first phase… | 0 | 0 | [0.51348484, 0.48651516] |
| 2015-10-01 | 1.32e-02 | ABBV | 1 | rt AT_USER kris jenners ‘ top picks are $ abbv… | 1 | 1 | [0.4781778, 0.5218222] |
| 2015-10-01 | -1.27e-02 | AEP | 0 | aap advance auto parts inc . yield URL $ aap $… | 1 | 0 | [0.48092097, 0.519079] |
| 2015-10-01 | 1.38e-02 | AMGN | 1 | amgen $ amgn showing bearish technicals with s… | 0 | 1 | [0.50068355, 0.49931648] |
- 通过市场情绪预测
| Sentiment | Tweet | predictions | true_labels | pred_probs |
|---|---|---|---|---|
| 0 | i just tried to trip my cat. but i kicked him … | 0 | 0 | [0.9928254, 0.00717464] |
| 0 | really lovingat_user at the moment! sad that t… | 0 | 0 | [0.99885607, 0.0011439769] |
| 1 | at_user keep up the good work love the songs…. | 1 | 1 | [0.021485569, 0.9785145] |
| 1 | at_user i’m excited to see it | 1 | 1 | [0.0004572706, 0.9995427] |
| 1 | at_user ooooh!!!!! | 1 | 1 | [0.008678274, 0.99132174] |
与baseline对比
模型的性能与Stock movement prediction from tweets and historical prices中使用的基线模型进行了比较。以下是考虑的基线模型:
-
RAND:一个预测器,随机猜测上涨或下跌。
-
ARIMA:仅使用价格信号的高级技术分析方法,自回归积分移动平均法
-
RANDFOREST:使用Word2vec文本表示的判别性随机森林分类器
-
TSLDA:一种生成主题模型,同时学习主题和情感
-
HAN:一种具有分层注意力的最先进的判别性深度神经网络
| Models | Accuracy | MCC |
|---|---|---|
| RAND | 50.89 | −0.002266 |
| ARIMA | 51.31 | −0.020588 |
| RANDFOREST | 50.08 | 0.012929 |
| TSLDA | 54.07 | 0.065382 |
| HAN | 57.64 | 0.0518 |
| BERT 直接预测 | 53 | 0.0344 |
| BERT 通过市场情绪预测 | 52.6 | 0.026 |
此外,还将提出的模型的性能与Stock movement prediction from tweets and historical prices中介绍的模型进行比较。以下是StockNet的变体:
- TECHNICALANALYST:仅使用历史价格的生成StockNet。
- FUNDAMENTALANALYST:仅使用推文信息的生成StockNet。
- INDEPENDENTANALYST:没有时间辅助目标的生成StockNet。
- DISCRIMINATIVEANALYST:直接优化似然目标的判别性StockNet。
| StockNet variations | Accuracy | MCC |
|---|---|---|
| TECHNICAL ANALYST | 54.96 | 0.016456 |
| FUNDAMENTAL ANALYST | 58.23 | 0.071704 |
| INDEPENDENT ANALYST | 57.54 | 0.03661 |
| DISCRIMINATIVE ANALYST | 56.15 | 0.056493 |
| HEDGEFUND ANALYST | 58.23 | 0.080796 |
| BERT 直接预测 | 53 | 0.0344 |
| BERT 通过市场情绪预测 | 52.6 | 0.026 |
结论
尽管BERT在大型文本语料库上进行了训练,并在许多语言任务中超过了最先进的结果,但它仍然无法实现比专用于StockNet变体(如基本分析师和对冲基金分析师)更高的准确性和MCC。
在进一步分析原因后,发现主要原因是StockNet中使用了时间辅助注意机制。它作为去噪正则化器,有助于模型过滤噪声,例如市场上升趋势时暂时上升的正向运动,并帮助模型通过去噪来聚焦于主要目标并进行良好的泛化。尽管BERT通过掩码自我注意力学习上下文,但这种任务特定的注意机制在这些模型中并不存在。
不过通过微调策略的优化,可以看出微调后的BERT模型相较于基础模板有非常明显的优化,由于个人PC的性能限制在面对大型文本语料库的训练无能为力,所以可以认为在拥有充足的算力的环境,以及在不过拟合的同等轮次的情况下,微调BERT能为BERT模型带来更大的准确性的MCC的区别。