摘要
股票走势预测是一个具有挑战性的问题:市场高度随机,我们需要根据混乱的数据做出时间相关的预测。我们处理了这三个复杂性,并提出了一种新颖的深度生成模型,联合利用文本和价格信号进行这项任务。与判别式或主题建模不同,我们的模型引入了循环的连续潜变量,以更好地处理随机性,并使用神经变分推理来解决后验推理的不可解性。我们还提供了一个具有时间辅助的混合目标,以灵活地捕捉预测依赖关系。我们在一个新收集的股票走势预测数据集上展示了我们提出的模型的最先进的性能。
介绍
股票走势预测一直吸引着投资者和研究者(Frankel,1995;Edwards等,2007;Bollen等,2011;Hu等,2018)。我们提出了一个模型,从推特和历史股价中预测股票价格走势。 在自然语言处理(NLP)中,公共新闻和社交媒体是股市预测的两个主要内容资源,使用这些资源的模型通常是判别式的。其中,经典的研究在很大程度上依赖于特征工程(Schumaker和Chen,2009;Oliveira等,2013)。随着深度神经网络(Le和Mikolov,2014)的普及,基于事件的方法被用来研究结构化的事件表示(Ding等,2014、2015)。
最近,胡等人(2018)提出了一种利用层次注意机制直接从文本中挖掘新闻序列的方法,用于股票趋势预测。然而,股票走势预测被广泛认为是一个困难的问题,因为市场具有很高的随机性:股票价格很大程度上受到新信息的驱动,呈现出随机游走模式(Malkiel, 1999)。与其仅使用确定性特征,生成主题模型被扩展为联合学习主题和情感,用于这个任务(Si et al., 2013; Nguyen and Shirai, 2015)。与判别模型相比,生成模型在描述市场信息到股票信号的生成过程以及引入随机性方面具有天然的优势。然而,这些模型用词袋表示混乱的社会文本,并采用简单的离散潜变量。
从本质上讲,股票走势预测是一个时间序列问题。现有NLP研究中没有解决走势预测之间的时间依赖性问题。例如,当一家公司在交易日d1遭遇重大丑闻时,通常其股价会在接下来的交易日直到d2呈现下跌趋势,即$[d1, d2]$。如果一个股票预测器能够识别这种下跌模式,它可能会对$[d1, d2]$期间所有走势预测都有益。否则,在这个区间内的准确率可能会受到损害。这种预测依赖性是由于公共信息(例如公司丑闻)需要时间才能被吸收到随时间变化的走势中(Luss and d’Aspremont, 2015),因此在时间上相近的预测中大部分是共享的。
我们提出了一个模型,旨在解决上述模型高市场随机性、混乱市场信息和时间相关预测方面的突出研究差距。StockNet,一种用于股票运动预测的深度生成模型。 为了更好地结合随机因素,我们从用循环、连续潜在变量建模的潜在驱动因素中生成股票运动。受变分自编码器(VAEs;Kingma and Welling, 2013; Rezende et al., 2014)的启发,我们提出了一种具有变分结构的新颖解码器,并推导出一个用于端到端训练的循环变分下界(第5.2节)。
据我们所知,StockNet是第一个用于股票运动预测的深度生成模型。 为了充分利用市场信息,StockNet直接从数据中学习,而不需要预先提取结构化事件。我们通过参考基本信息(例如推文)和技术特征(例如历史股价)(第5.1节)来构建市场来源。3为了准确地描述预测依赖性,我们假设股票的运动预测可以从学习其滞后窗口内的历史运动中受益。我们提出交易日对齐作为框架基础(第4节),并进一步提供了一种新颖的多任务学习目标(第5.3节)。 我们在一个新收集的数据集上对StockNet进行了股票运动预测任务的评估。与强大的基线相比,我们的实验表明,StockNet通过结合来自Twitter和历史股价列表的数据,实现了最先进的性能。
$y = 1(p^c_d > p^c_{d-1} )$
其中,$p^c_d$ 表示经过调整的收盘价,该收盘价已考虑了影响股价的公司行为,例如分红和拆股。调整后的收盘价价格被广泛用于预测股价走势(Xie et al., 2013)或金融波动性(Rekabsaz et al., 2017)。
数据收集
在金融领域,股票分为9个行业: 基础材料、消费品、医疗保健、服务、公用事业、综合企业、金融、工业品和技术。 5由于交易量高的股票往往在Twitter上讨论得更多,我们选择了88只股票在2014年1月1日至2016年1月1日两年间的价格走势作为目标,这些股票来自综合企业中的8只股票和其他8个行业中按市值排名前10的股票(详见补充材料)。
我们观察到有一些目标的涨跌幅度非常小。在一个三分类的股票趋势预测任务中,一种常见的做法是通过设置上下阈值来将这些涨跌幅度划分为另一个“保持”类别(Hu et al., 2018)。
由于我们的目标是二分类地从社交媒体中识别出股价变化,我们设置了两个特定的阈值,-0.5%和0.55%,并简单地移除了涨跌幅度在这两个阈值之间的38.72%的选定目标。涨跌幅度≤-0.5%和>0.55%的样本分别用0和1标记。这两个阈值是为了平衡两个类别而选择的,导致整个数据集中有26,614个预测目标,其中49.78%和50.22%属于两个类别。
我们按时间顺序划分它们,2014年1月1日至2015年1月8日之间的20,339次涨跌用于训练,2015年1月8日至2015年10月1日之间的2,555次涨跌用于验证,2015年10月1日至2016年1月1日之间的3,720次涨跌用于测试。 我们的数据集有两个主要组成部分:一个Twitter数据集和一个历史价格数据集。
我们在Twitter官方许可下访问Twitter数据,然后通过查询由纳斯达克股票代码组成的正则表达式来检索特定股票相关的推文,例如,“$GOOG\b”表示谷歌公司。我们使用NLTK包(Bird et al., 2009)对推文文本进行预处理,并对超链接、主题标签和“@”标识符进行特殊处理。为了缓解稀疏性问题,我们进一步通过确保每个语料库在滞后期内至少有一条推文来过滤样本。我们从雅虎财经7提取了88只选定股票的历史价格来构建历史价格数据集。
模型概览
我们提供了数据对齐、模型分解和模型组件的概述。 如第1节所述,我们假设预测交易日d的走势可以从预测其前一交易日的走势中受益。然而,由于样本独立性的一般原则,直接在具有临近目标日期的样本之间建立联系对于模型训练是有问题的。
作为一种替代方案,我们注意到,在以交易日d为目标的样本中,除了d之外,还可能有其他交易日存在于其滞后期中,可以模拟接近d的预测目标。受此启发,并借鉴多任务学习(Caruana, 1998),我们不仅对d进行走势预测,还对滞后期中存在的其他交易日进行预测。
例如,如图2所示,对于以2012年8月7日为目标的样本和5天的滞后期,2012年8月3日和2012年8月6日是滞后期中合格的交易日,我们也使用这个样本中的市场信息对它们进行预测。这些预测之间的关系可以在一个样本的范围内被捕捉到。
如上面的例子所示,并不是滞后期中的每一个日期都是合格的交易日,例如周末和节假日。为了更好地组织和利用输入,我们将交易日,而不是现有研究中使用的日历日,作为构建样本的基本单位。为此,我们首先找到一个样本中提到的所有T个合格的交易日,换句话说,在时间间隔$[d - ∆d + 1, d]$中存在的交易日。为了清晰起见,在一个样本的范围内,我们用来索引这些交易日, 每个交易日都映射到一个实际(绝对)交易日dt 。然后我们提出交易日对齐:我们通过将它们对齐到这 T 个交易日来重新组织我们的输入,包括推文语料库和历史价格。具体来说,在第 t 个交易日,我们从$[d_{t-1}, d_t)$中的语料库Mt 中识别市场信号,并且每个都映射到一个实际(绝对)的交易日 $d_t$ 。
然后我们提出交易日对齐:我们通过对齐它们到这些 T 个交易日来重新组织我们的输入,包括推文语料库和历史价格。具体来说,在第 t 个交易日,我们从 $[d_{t−1}, d_t) $中的语料库 $M_t$ 中识别市场信号,并从 $d_{t−1}$ 中的历史价格 $p_t$ 中识别,用于预测 $d_t$ 上的运动 $y_t$ 。
我们在图 2 中提供了一个对齐的示例。因此,样本中的每个单元都是一个交易日,我们可以预测一系列运动 $y = [y_1, . . . , y_T ]$。主要目标是 $yT$,而剩余的 $y^∗ = [y_1, . . . , y_{T −1}]$ 作为时间辅助目标。我们使用这些目标来提高预测准确性(第 5.3 节)。
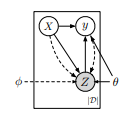
我们模拟了图1所示的生成过程。我们将观察到的市场信息编码为一个随机变量$X = [x_1; . . . ; x_T ]$,从中我们生成用于我们的预测任务的潜在驱动因子$Z = [z_1; . . . ; z_T ]$。为了前面提到的多任务学习目的,我们旨在建模条件概率分布$pθ(y|X) = \int_ Z p_θ (y, Z|X)$,而不是$pθ(y_T |X)$。 我们为生成写下以下因式分解,
$pθ(y,Z|X) = pθ (y_T|X, Z) pθ (z_T|z<t, X)$
$\prod^{T-1}_{t=1}pθ (y_t|x≤t, z_t) pθ (z_t|z<t, x≤t, y_t)$
对于给定的T个向量的索引矩阵$[v_1; . . . ; v_T]$,我们用$v<t$和$v≤t$表示子矩阵$[v_1; . . . ; v_{t−1}]$和子矩阵$[v_1; . . . ; v_t]$,分别。由于$y∗$在生成时是已知的,我们使用后验$pθ (zt|z<t, x≤t, yt),t < T$来更准确地结合市场信号,只在生成$zT$时使用先验$pθ(zT |z<T , X)$。此外,当$t < T$时,$y_t$与$z<t$独立,而我们的主要预测目标$yT$则通过一个时间注意力机制(第5.3节)使之依赖于$z<T$。
我们在图2中展示了StockNet对上述生成过程的建模。简而言之,StockNet模型由三个主要部分组成,按照自下而上的方式:
- 市场信息编码器(MIE),将推文和价格编码为X;
- 变分运动解码器(VMD),用X,y推断Z,并用X,Z解码股票运动y;
- 注意力时序辅助(ATA),通过注意力机制整合时序损失进行模型训练。
模型组件
我们的模型(MIE,VMD,ATA)的组成部分和我们估计模型参数的方法如下。