前言
本项目旨在对高后果区内进出车辆进行识别,在参考了生产项目中,其中使用的模型是yolov3,所以初步设想是使用同样的yolo框架考虑兼容性,加之考虑到目前yolo已经更新至yolov8,所以我在挑选使用模型时主要参考了性能指标折中选择了yolov5模型,以下两图展示了yolov3,yolov5及最新的yolov8的性能差距
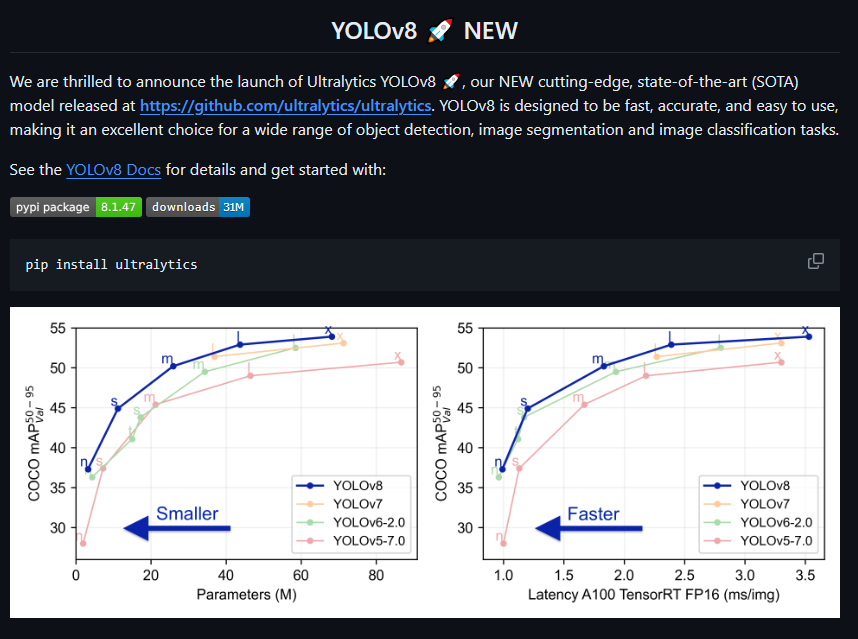
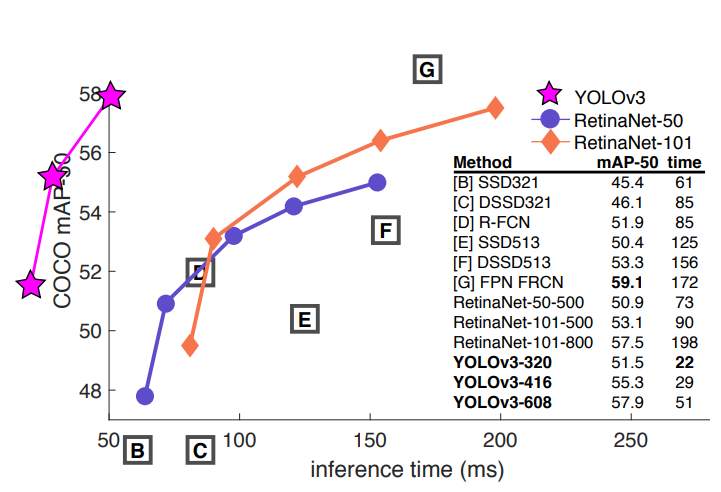
此外,因目前yolov5模型已经完成,基于对现场硬件设施的考量和技术探索的角度,后续打算尝试使用百度paddle框架尝试性能差距,并且可以考虑使用ResNet等模型进行移动端迁移,让模型脱离固定摄像头,使用手机进行替代
介绍
高后果区(High Consequence Areas,HCAs)是指管道如果发生泄漏会严重危及公众安全和(或)造成环境较大破坏的区域。典型的高后果区为人口密集区和环境敏感区,输气管道对于河流、湖泊、自然保护区等环节敏感区危害相对较小,因此环境敏感类高后果区主要是针对输油管道。
高后果区一直存在被重车或重型机构碾压的危险,发生在高后果区的管道泄漏事故可能会对管道沿线周边的人员安全、环境安全造成较大危害,进而产生较大社会影响。在非高后果区内的管道泄漏事故影响主要是针对管道企业内部,应避免在高后果区内发生管道泄漏,或者因管道泄漏导致的次生灾害。
所以及时获知有无安全隐患闯入高后果区并及时报警对于安全生产是不可或缺的一环,所以在该问题中本项目完成了必要的车辆识别分类、高后果区闯入报警以及移动端部署内容
需求分析与实现
高后果区的8项检测内容,管线周边机械作业或重型车辆监测,通过监测,明烟明火识别监测,单/双人巡检监测,吊装作业安全监测,动火作业监测,管道附属设施损坏及偷盗监测,地质灾害监测,管线占压监测
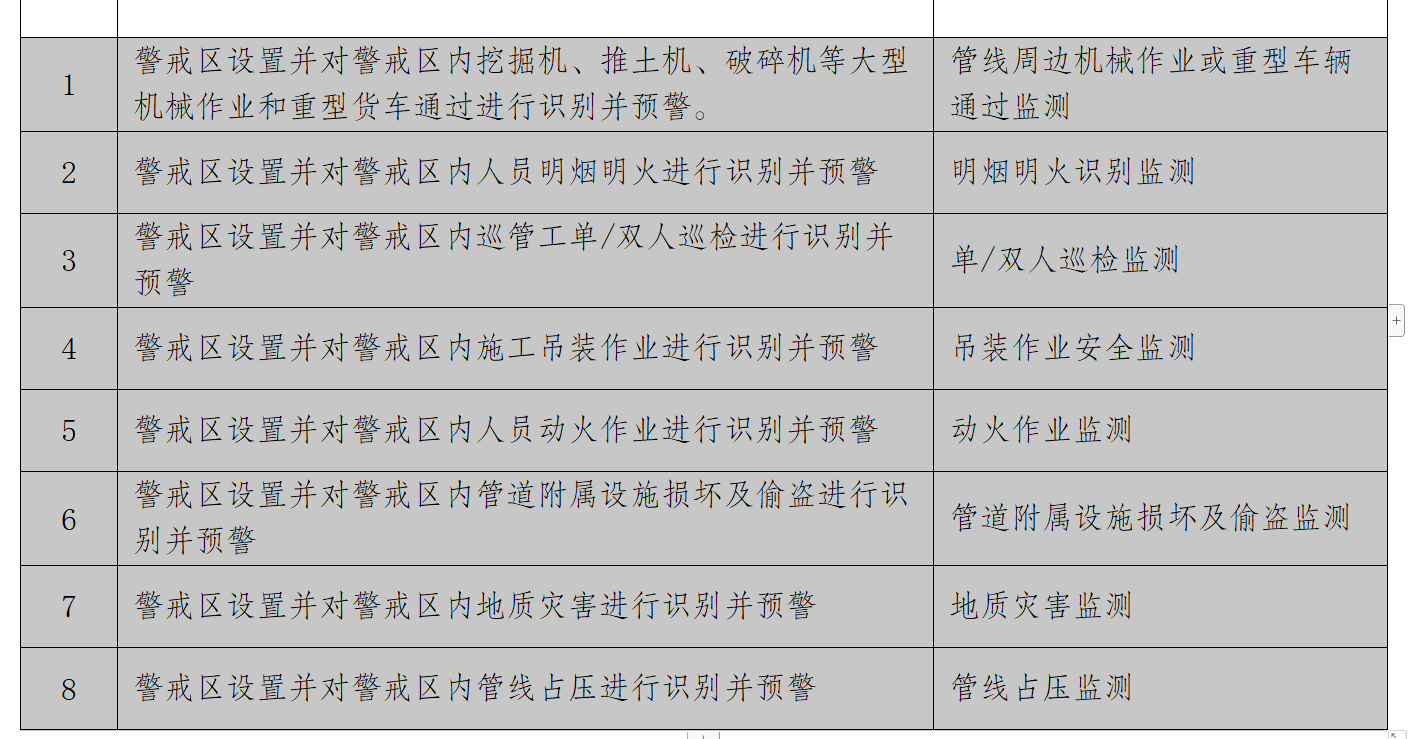
按照目前的模型实现部分,可以完成管线周边机械作业或重型车辆监测,单/双人巡检监测,其中通过检测,管线占压监测依然可以使用yolo模型实现区域闯入模型,不过区域闯入模型涉及实施视频数据和区域划线
关于地质灾害识别部分,需要花费时间训练新模型,可以放在后续规划中,但目前工作重心不在之上,暂且搁置。另外关于明烟明火识别监测,吊装作业安全监测,动火作业监测目前没有特别好的思路
采用技术
yolo模型
You Only Look Once”是一种使用卷积神经网络进行目标检测的算法。YOLO是其中速度较快的物体检测算法之一。虽然它不是最准确的物体检测算法,但是在需要实时检测并且准确度不需要过高的情况下,它是一个很好的选择。
与识别算法相比,检测算法不仅预测类别标签,还检测对象的位置。因此,它不仅将图像分类到一个类别中,还可以在图像中检测多个对象。该算法将单个神经网络应用于整个图像。这意味着该网络将图像分成区域,并为每个区域预测边界框和概率。这些边界框是由预测的概率加权的。
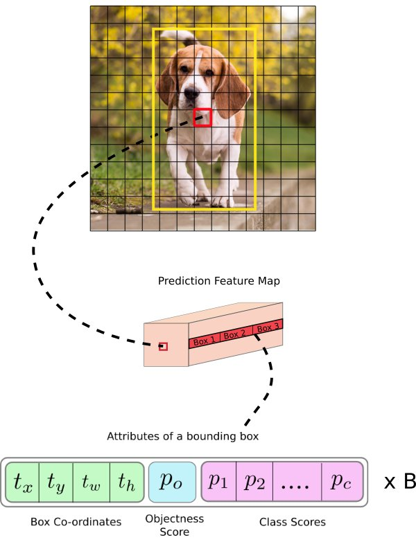
关于yolo模型不同代号的含义:
s:这是yolo系列中最小的模型。“s” 代表 “small”(小)。该模型在计算资源有限的设备上表现最佳,如移动设备或边缘设备。 yolov5s的检测速度最快,但准确度相对较低。
m:这是 YOLOv5 系列中一个中等大小的模型。“m” 代表 “medium”(中)。YOLOv5m 在速度和准确度之间提供了较好的平衡,适用于具有一定计算能力的设备。
l:这是 YOLOv5 系列中一个较大的模型。“l” 代表 “large”(大)。YOLOv5l 的准确度相对较高,但检测速度较慢。适用于需要较高准确度,且具有较强计算能力的设备。
x:这是 YOLOv5 系列中最大的模型。“x” 代表 “extra large”(超大)。YOLOv5x 在准确度方面表现最好,但检测速度最慢。适用于需要极高准确度的任务,且具有强大计算能力(如 GPU)的设备。
n::这是 YOLOv5 系列中的一个变体,专为 设nano(如 NVIDIA Jetson Nano)进行优化。YOLOv5n 在保持较快速度的同时,提供适用于边缘设备的准确度。
onnx
ONNX即开放神经网络交换(Open Neural Network Exchange)是微软和Facebook提出用来表示深度学习模型的开放格式。所谓开放就是ONNX定义了一组和环境,平台均无关的标准格式,来增强各种AI模型的可交互性。
也就意味着无论开发者使用何种训练框架训练模型(比如TensorFlow/Pytorch/OneFlow/Paddle),在训练完毕后你都可以将这些框架的模型统一转换为ONNX这种统一的格式进行存储。同时ONNX文件不仅仅存储了神经网络模型的权重,同时也存储了模型的结构信息以及网络中每一层的输入输出和一些其它的辅助信息。
下图为yolov3-tiny onnx的可视化结果
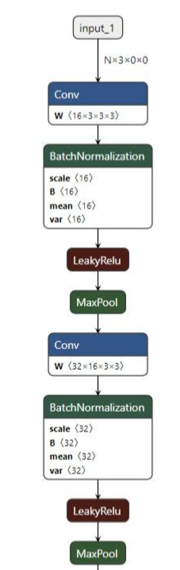

ncnn
ncnn 是由腾讯开源的为手机端极致优化的高性能神经网络前向计算框架。 ncnn 从设计之初深刻考虑手机端的部署和使用。 无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。 基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 APP,其中ncnn 目前已在腾讯多款应用中使用,如:QQ,Qzone,微信,天天 P 图等。
ncnn功能概述:
支持卷积神经网络,支持多输入和多分支结构,可计算部分分支
无任何第三方库依赖,不依赖 BLAS/NNPACK 等计算框架
纯C++ 实现,跨平台,支持 Android / iOS 等
ARM Neon 汇编级良心优化,计算速度极快
精细的内存管理和数据结构设计,内存占用极低
支持多核并行计算加速,ARM big.LITTLE CPU 调度优化
支持基于全新低消耗的 Vulkan API GPU 加速
可扩展的模型设计,支持 8bit 量化 和半精度浮点存储,可导入 caffe/pytorch/mxnet/onnx/darknet/keras/tensorflow(mlir) 模型
支持直接内存零拷贝引用加载网络模型
可注册自定义层实现并扩展

pyqt
PyQt是Qt框架的Python语言实现,由Riverbank Computing开发,是最强大的GUI库之一。PyQt提供了一个设计良好的窗口控件集合,每一个PyQt控件都对应一个Qt控件,因此PyQt的API接口与Qt的API接口很接近,但PyQt不再使用QMake系统和Q_OBJECT宏
PyQt5特性如下:
基于高性能的Qt的GUI控件集。
能够跨平台运行在Linux、Window和Mac OS系统上。
可以使用成熟的IDE进行界面设计,并自动生成可执行的Python代码。
提供一整套种类齐全的窗口控件。

数据集
目前数据集主要来源于开源数据集:https://b2n.ir/vehicleDataset
该数据集主要用于训练yolo模型和resnet模型,虽然在实际的训练效果中resnet在图片识别的Acc达到了99.7%,但是考虑到在对视频的识别和模型的移动端迁移问题,最终选择放弃
在多次试验后发现,虽然在自己训练后的yolov5模型的检测准确率更高,但是在移动端的detection模块中,还是官方开源的yolov5s模型最快,最后在选择模型阶段考虑到结果统一还是决定放弃自行训练的模型,转而选择全面使用官方提供的yolov5s模型
Paddle框架
TODO
该部分内容目前已经被放弃实现
ResNet网络
TODO
该部分经过尝试后验证虽然在图片识别效果相较于yolo响应更快,准确度更高,但是在视频识别和模型迁移的能力中明显yolo更占优,所以放弃
模型迁移
目前模型已经成功迁移到安卓作为移动端,完成此项研究的目的在于,考虑到现场大多使用固定式摄像头,或者安眼等笨重的设备,受限于供电设备的限制是一定存在视野盲区的,而解决视野盲区的问题,无非是增加新的监控设备,依旧是成本问题,那么是否存在廉价且可行的解决方案呢?
正是基于这样的想法,将模型向移动端部署则旨在解决这一问题,相较于固定式摄像头需要破土添线,或者安眼摄像头需要额外租凭,防爆手机(或者其他被信任的安卓系统设备均可)无论是先期成本还是更换维护的成本相较而言都显得廉价的多。
此外,相较于上述监控设备的笨重,采取移动设备进行监控则更是解放了被硬件限制的监控角度,完成真正的无死角监控,加之通讯模块可以实现远程传输,也是对网线成本问题的解决,做到随用随传,无死角监控
解决问题
目前主要通过yolo和pyqt完成了PC端部署,借助onnx和ncnn在Android studio完成了移动端部署。
在笔者实现该项目前,现有的高后果区识别项目主要用于实现人的识别,主要功能为:
劳保穿戴、明烟明火、外来入侵、接打电话、吸烟、人员异常倒地、进出站人数统计、单/双人巡检、吊装作业安全监测、高处作业安全带佩戴、动火作业、监测、人脸识别等。
基于对以往项目的了解,该模型的主要使用了yolov3模型进行识别,所以在此基础上和技术提升和进步以及版本兼容等问题的综合考量上,我并没有选择使用最新的yolov8,而是选择了yolov5
为什么选择yolov5?
如果要回答这个问题,我们需要从性能和大小两方面来看
性能:在性能这一模块则不得不提到yolov4,这也是yolov5的上一代,相较于yolov3的集大成者,采用了CSPDarknet53+SPP+PAN+YOLOv3的框架,通过堆料的方式,增加了Weighted-Residual-Connections (WRC)、Cross-Stage-Partial-connections (CSP) 、Cross mini-Batch Normalization (CmBN)、Self-adversarial-training (SAT)、Mish-activation、Mosaic、data augmentation、CmBN、DropBlock regularization、CIoU loss技术实现了一种高效而强的目标检测模型,这些技巧主要应用于下面这些方面:
用于backbone的BoF:CutMix和Mosaic数据增强,DropBlock正则化,Class label smoothing
用于backbone的BoS:Mish激活函数,CSP,MiWRC
用于检测器的BoF:CIoU-loss,CmBN,DropBlock正则化,Mosaic数据增强,Self-Adversarial 训练,消除网格敏感性,对单个ground-truth使用多个anchor,Cosine annealing scheduler,最佳超参数,Random training shapes
用于检测器的Bos:Mish激活函数,SPP,SAM,PAN,DIoU-NMS
此外作者还通过在输入网络分辨率,卷积层数,参数数量和层输出(filters)的数量之间找到最佳平衡,而这努力最终实现了yolov4在性能上的飞跃,而继承了这一框架的yolov5也是其完美性能的体现,在论文YOLOv4: Optimal Speed and Accuracy of Object Detection中大量的实验充分的证明了这一点
大小:在yolov5命名之初,大家对其有着非常大的争议,因为因为YOLOV5相对于YOLOV4来说创新性的地方很少,相较于yolov4和yolov3那样的大踏步式的变革,yolov5的框架则几乎没有改变,也正是基于这样的缘由yolov5的开发者们并没有将yolov4进行性能比较
但是不同于性能的一成不变,在yolov5的模型轻量化上则有着长足的进步,以使用darknet框架的yolo模型举例,yolov4有2444mb而yolov5则只有27mb,足足减少了90%,而这一切都是在不损失准确度指标的情况下实现的。
因此总结起来便是选择yolov5的原因,它拥有着作为集大成者的yolov4的模型性能和准确度,也有着轻量级的模型大小,快速的推断速度和与yolov3的优秀兼容。
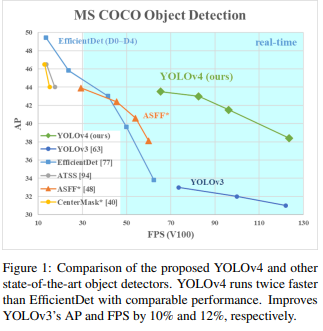
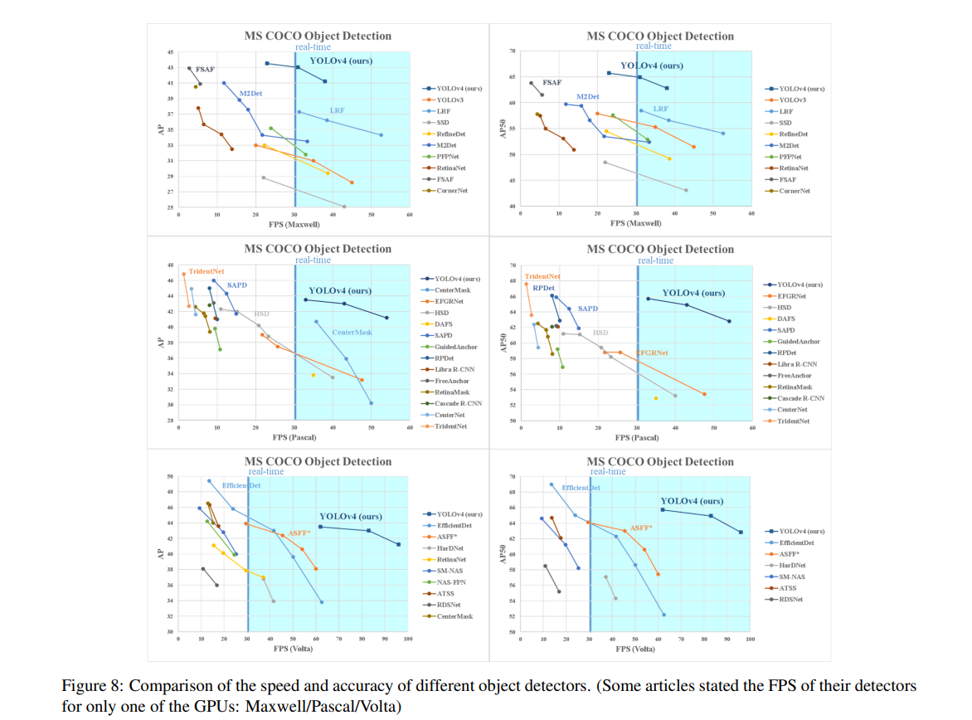
而除了对模型的更新外还完成了管线周边机械作业或重型车辆监测,单/双人巡检监测,通过检测,管线占压监测并将这些检测模块在双端完成了部署,解决了高后果区的四项检测问题
在完成模型训练和功能完善的同时还实现了模型的迁移,将训练好的模型向移动端部署,做到脱离固定的监控设备,降低监控设备的使用成本,同时也通过移动设备的灵活性,做到以足够低的成本实现监控无死角,实现安全生产
程序框图及使用逻辑
移动端项目程序框图:
第一版(用户登录+注册+图片识别+拍照识别):
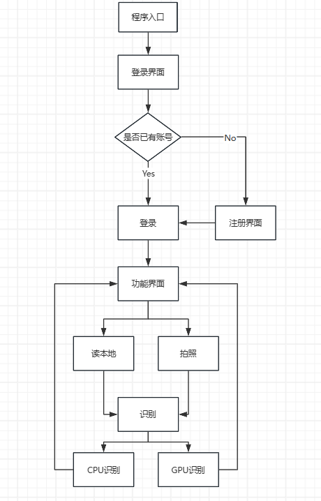
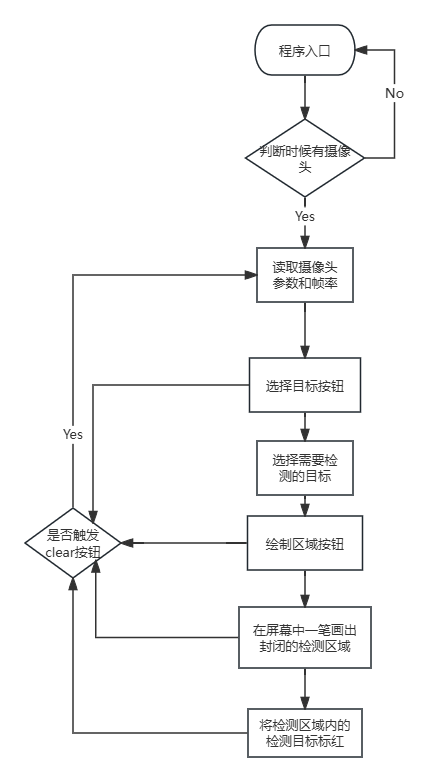
第二版(视频实时识别+区域闯入)
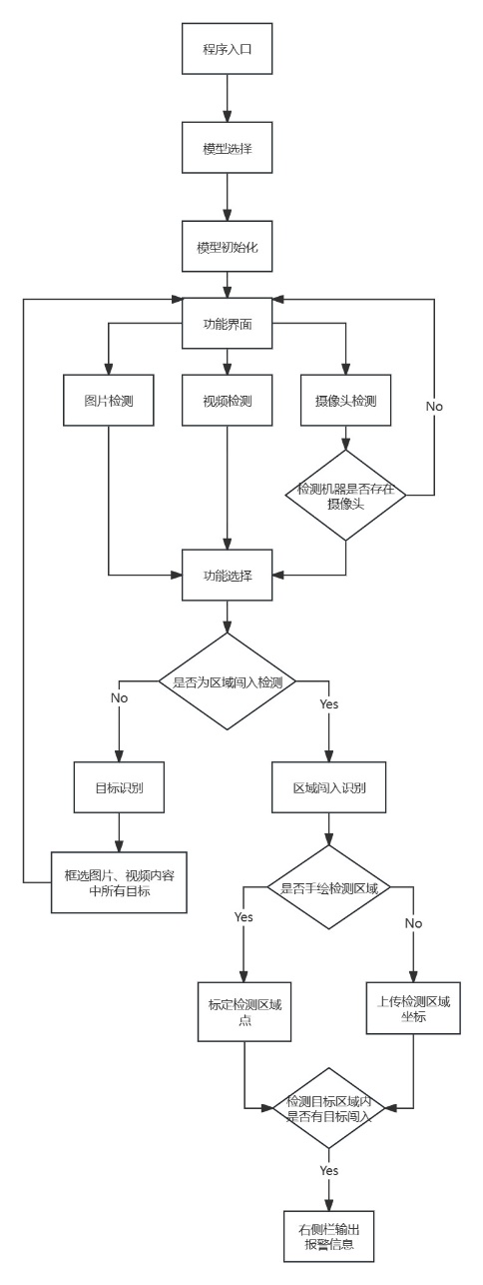
PC端项目架构:
项目架构
移动端项目架构:
第一版(用户登录+注册+图片识别+拍照识别):
第二版(视频实时识别+区域闯入)
PC端项目架构:

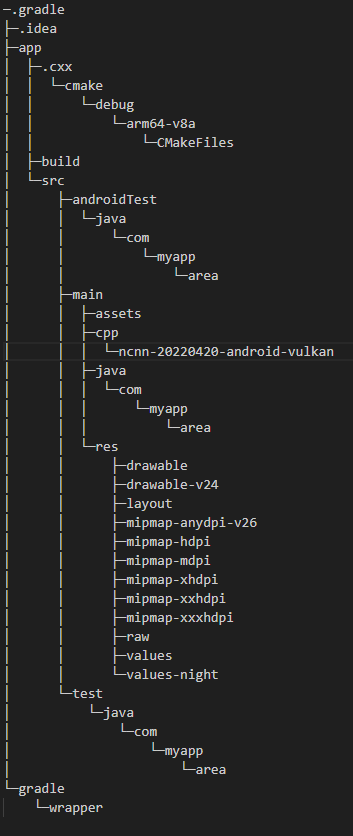
使用Yolov5实现的detection效果图展示(初期效果图)

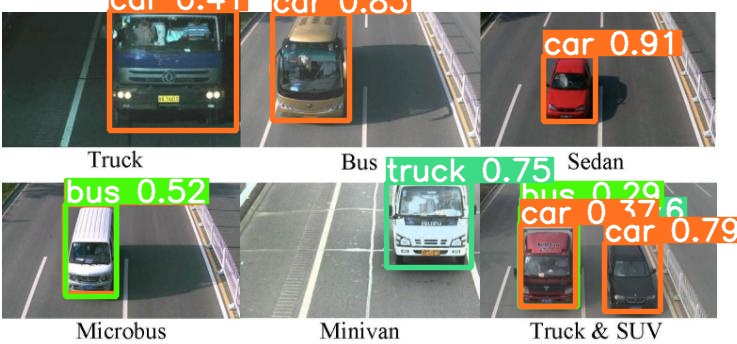

效果展示
移动端项目架构:
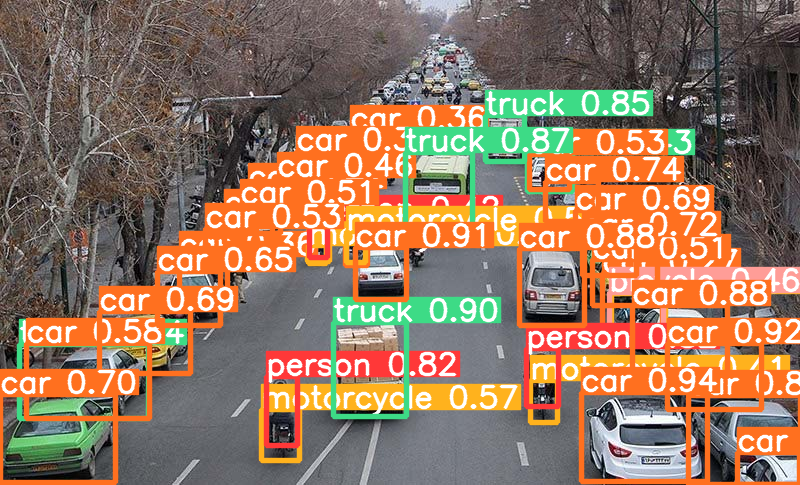
第一版(用户登录+注册+图片识别+拍照识别):
用户登录
用户注册
功能总览

拍照识别

读图识别

第二版(视频实时识别+区域闯入)
目标识别
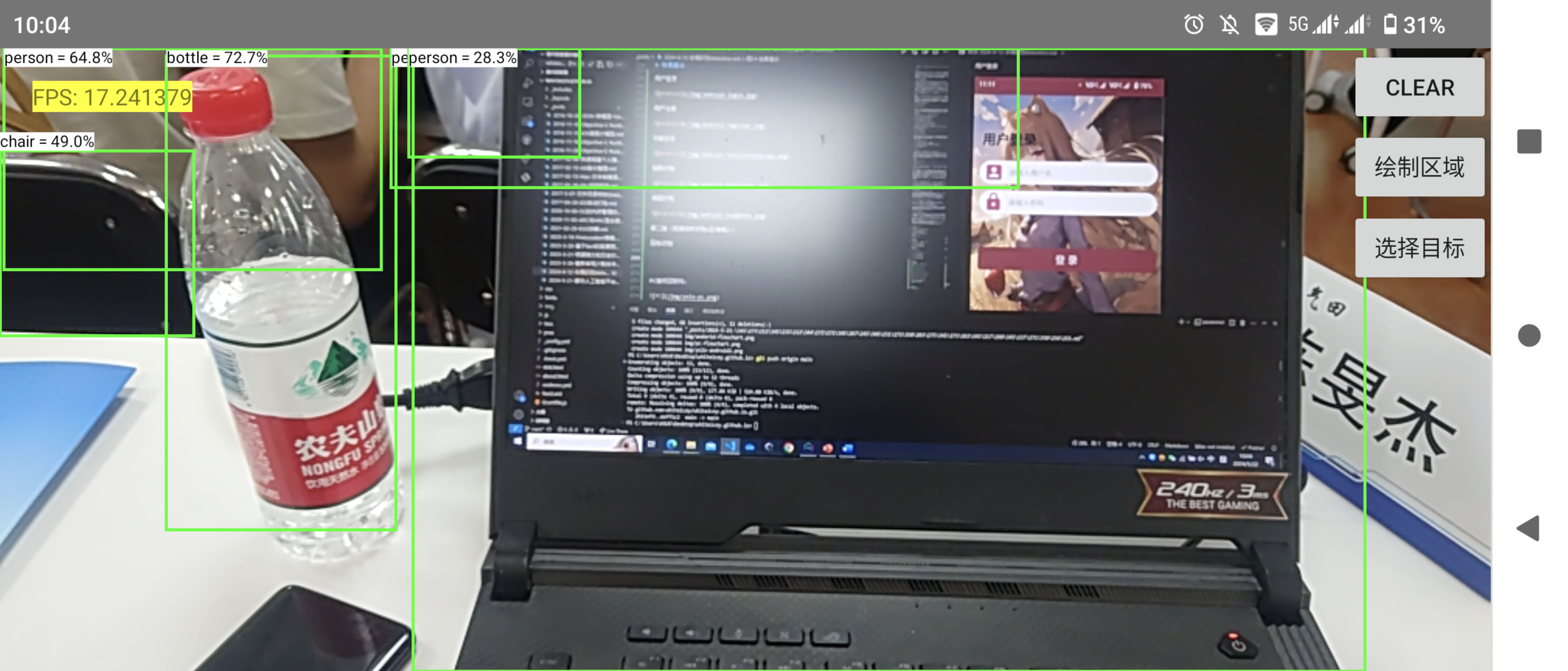
检测目标选择
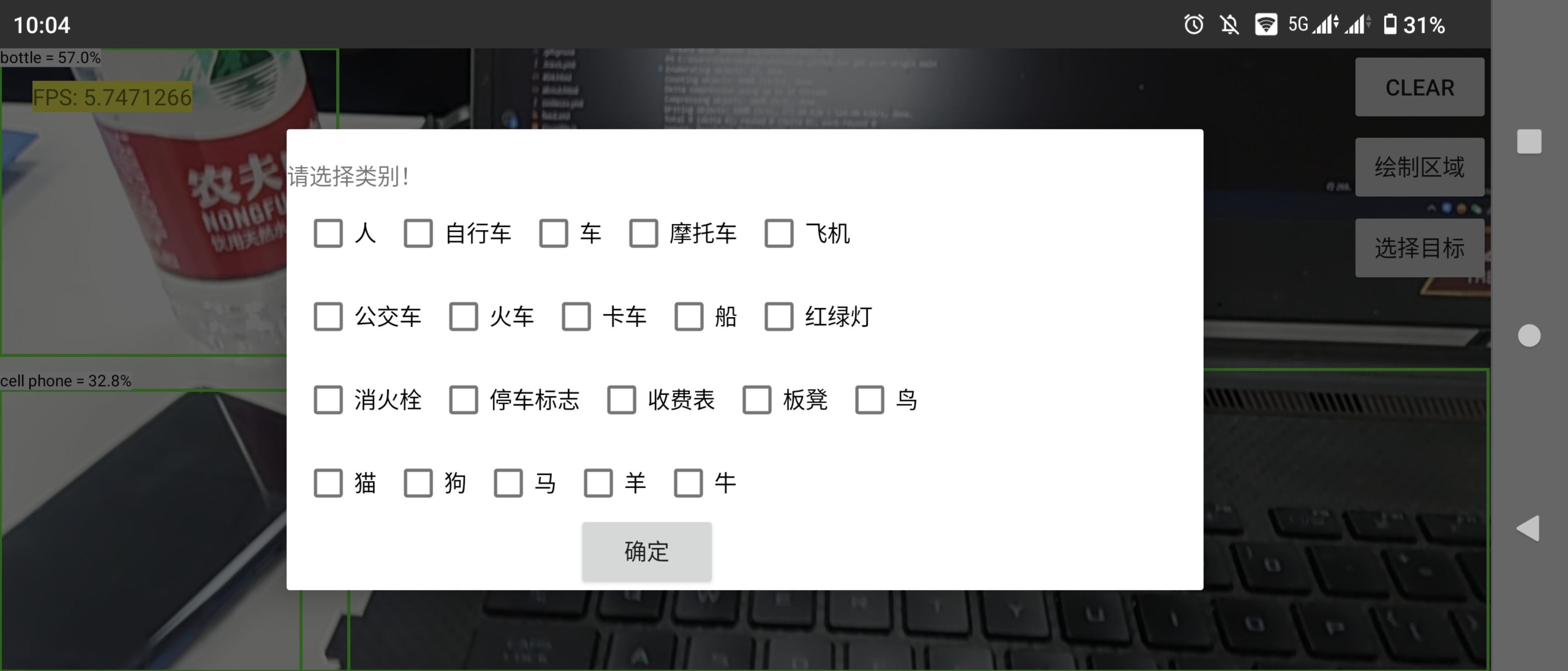
检测区域绘制
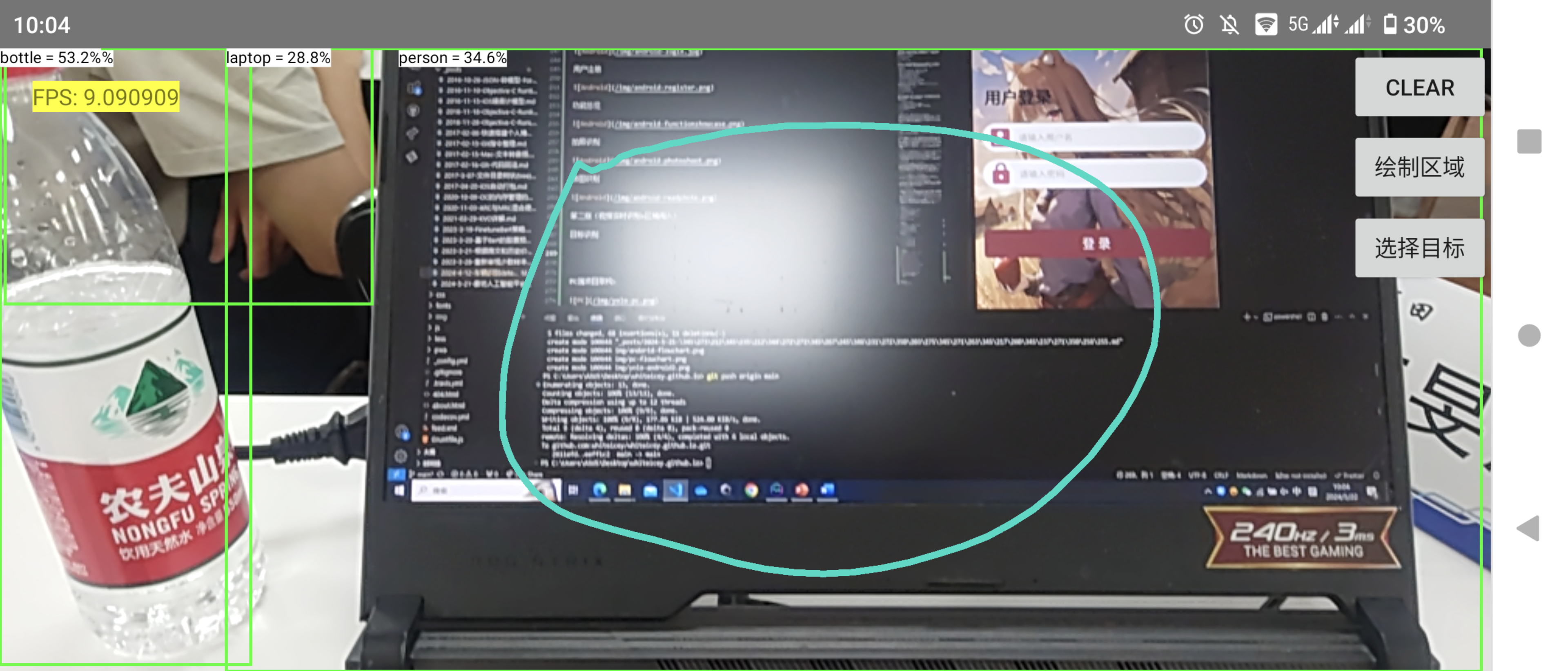
区域内目标检测

PC端项目架构:
图片识别

图片区域识别及报警

视频/摄像头识别与区域闯入检测


后续计划以及TodoList
-
完善文档,目前进度完成远超文档完善程度,文档依旧按照原计划在本人博客上进行更新,详情请参考:https://whiteicey.github.io/ 目前文档进度已经跟进了开发进度,后续根据需求再考虑完善方向 -
目前在onnx剪枝和ncnn的协助下,尝试部署了无区域闯入版本的模型,全APP大小大约在120mb左右,认为在可接受范围内,后续尝试继续部署区域闯入模型在移动端目前已经将区域闯入模型在移动端上,功能部署上已达预期 -
地质灾害识别部分需要全部重新训练,根据后续需求再判断是否需要完成
-
关于明烟明火识别监测,吊装作业安全监测,动火作业监测目前还没有特别成熟的实现思路,暂时搁置明烟明火识别目前看来是有成熟的识别方案的(见下图),吊装作业安全监测,动火作业监测依旧搁置
-
本项目仅为技术验证服务,不尝试整合模型,因为实在不会软件开发
-
只有掌握技术才掌握定价权